
Spatial Pattern to Learn (Sp2Learn) presents a framework for accurate estimation of geospatial models from sparse field measurements using image processing and machine learning. The goal is to improve our understanding of the underlying physical phenomena and increase the accuracy of geospatial models. Sp2Learn allows users to explore the accuracy improvements when several image de-noising techniques with a decision tree machine learning technique are employed, and multiple remote sensing and terrestrial raster measurements are used.
For example, we provide test data to illustrate how to incorporate and mine slope, soil type and proximity to water bodies for predicting groundwater recharge and discharge (R/D) rate models - ground water models.
Sp2Learn can be viewed as an encapsulated workflow for:
- loading multiple raster files (images),
- integrating and mosaicking all raster data sets to form a stack with consistent spatial resolution as well as geographic projection,
- loading other files (boundaries, points or images) to create a mask for pixel selection purposes,
- integrating the existing stack of raster images with other masking information,
- selecting boundaries or image regions of interest and extracting variables from the stack of images,
- performing data-driven modeling of selected input and output variables,
- analyzing data-driven model to assign a relevance coefficient to input variables, and
- mapping the data-driven model at a pixel level to spatial domain.
All aforementioned steps are supported by visualizations (colorful, gray-scale or pseudo-color) of input, intermediate, and output data sets, as well as the data models.
In order to bring together so much functionality, the architecture of Sp2Learn leverages several technologies. The majority of the Sp2Learn code is based on:
- Image to Learn (Im2Learn) developed at NCSA with additional calls to:
- HDF5 library developed by NCSA and
- MODIS Reprojection Tool (MRT) to perform geographic re-projection developed by NASA.
Groundwater recharge and discharge modeling
We focused on the problem of modeling groundwater recharge and discharge rates.
The joint research of NCSA and Illinois State Water Survey (ISWS) combines the computer science and ground water science expertise, and leveraged numerical methods and image processing algorithms to efficiently estimate R/D rates.
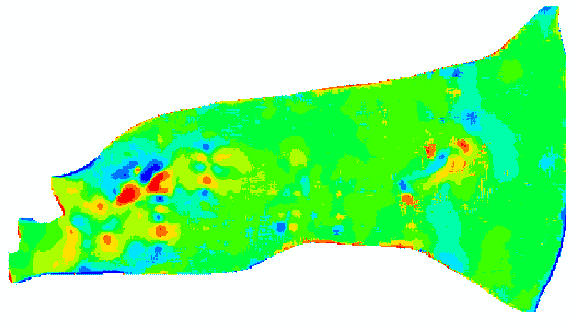
The work in progress is being tested against an intensively studied field site in Wisconsin: Results of pattern analysis (cell-by-cell recharge estimation) from the recharge/discharge map of the Buena Vista Basin, Wisconsin.
SP2Learn was created as a joint collaboration between the Illinois State Water Survey (ISWS) and the National Center for Supercomputing Applications (NCSA) at UIUC. Funding support was provided by NCSA Faculty Fellow Program and ISWS, Groundwater division, and leveraged by our past funding provided by the National Aeronautics and Space Administration (NASA), and National Archive and Record Administration (NARA).
Team members
- Yu-Feng-Lin
Associate Hydrogeologist, Illinois State Water Survey and University of Illinois at Urbana-Champaign, UIUC - Peter Bajcsy
Research group ISDA, National Center for Supercomputing Applications, UIUC - Chulyun Kim
ISDA, National Center for Supercomputing Applications, UIUC
